Welcome to day 5 of 100 Days of Networks!
Wikipedia Edgelist Generator
If you would like to learn more about networks and network analysis, please buy a copy of my book!
Today, I have a special treat for you! I created a Wikipedia Edgelist Generator that you can use for knowledge discovery on any topic that interests you. You can find the crawler / edgelist generator here!
I wanted to build a tool for knowledge discovery, and something that could be used no matter the topic to create complex networks that are more interesting than the small networks that come with NetworkX, and more interesting than using somebody else's dataset. To me, there is nothing more interesting than my own research, and I don't like using other people's datasets for learning. I prefer to analyze my own constructed networks, and do two things at the same time:
- Improve my network analysis skills
- Learn something about a topic of interest at the same time.
Today, I created the edgelist generator, and you may use it. I have added some guidance regarding iterations and sleeps at the top of the notebook. Please be responsible or Wikipedia will block your IP and you will get nothing.
Knowledge Discovery
The point of the edgelist generator is knowledge discovery, on any topic. For instance, to build today's dataset, I searched for four things:
- Network Science
- Social Network Analysis
- Graph Theory
- Causal Inference
If you look at the code on github, you will be able to see where and how I did that. After four iterations/loops of the crawling and edgelist generation, those four searches built a network of OVER 9000!!! nodes. That is why I call this knowledge discovery. Each of those 9000+ nodes is a Wikipedia page on a related topic. You will understand this more if you continue reading below.
If I had done five iterations instead of four, I might have ended up with 50,000 nodes or more, which is more than I wanted for this dataset, and would query Wikipedia's API harder than I wanted to do. You should start with two iterations, check your results, and then increase RESPONSIBLY.
Network Analysis
I created a second notebook (which is nearly a duplicate of Day 4 but with today's data) for analyzing this network data. You can see the code/notebook here!
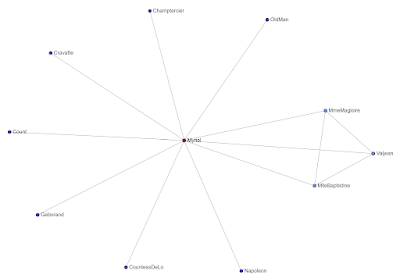
Previously, we used the Les Miserables network to learn a few fundamentals. From now on, we will use Wikipedia networks, as they are complex and more meaningful than character names. We can literally use the node names to continue our research into any topic of interest.
Today's created network is far more complex than Les Miserables.

Complex real-world networks often look like this, when rendered. This looks useless, like a big spiderweb that we cannot hope to pull insights out of, except maybe a few of the peripheral nodes sticking out, but that is completely wrong. A lot of people get stuck at Whole Network Analysis (WNA), and this series will absolutely show you how to pull insights from any network, simple or complex.

For today's update, the edgelist generator is the most important thing, as it is useful and we will use it to create interesting datasets during the course of this adventure. I have other topics in mind that I would like to understand.
Today, I chose the four 'seed searches' because they are all related:
- Network Science is a broader domain, like Data Science
- Social Network Analysis falls under Network Science
- Graph Theory was the origin that led to Network Science
- Causal Inference uses directed graphs to infer causality
I was especially interested to see the overlap between Causal Inference and the rest, and I will explore that in later days.
The generator itself requires some understanding, so I will keep the analysis light today. We will just look at a few ego networks, and discuss what we can see and do with the information.
It is always useful to look at Page Rank and centralities, to identify important nodes. That is always a good place to start after a graph has been constructed.

Very cool. We can see that the page "Glossary of graph theory" has a drastically higher Page Rank value than anything else. Let's take a look at the ego network for that node.

This is a complex ego network! There is a lot of connectivity between the alter nodes, and this is not at all a star network! This is a complex ecosystem of information having to do with Graph Theory. But this is hard to read. Check out the Jupyter notebook and you will see how to get a list of nodes.
What nodes have we uncovered? What interesting Wikipedia pages and topics have we found? Let's take a look. Here are just the first twenty nodes out of seventy-seven:
- Acyclic graph
- Arborescence (graph theory)
- Biconnected graph
- Bipartite graph
- Block graph
- Bridge (graph theory)
- Cheeger constant (graph theory)
- Chordal bipartite graph
- Chordal completion
- Chordal graph
- Circle graph
- Claw-free graph
- Clique (graph theory)
- Clique graph
- Complete bipartite graph
- Complete graph
- Component (graph theory)
- Cubic graph
- Cut (graph theory)
- Cycle (graph theory)
Very cool. I can already see several things I have never heard of. This could lead me down some interesting rabbit holes of discovery and education. Each of these is a separate Wikipedia page, and you can also search other sources on the internet, such as Arxiv. Let's look at more interesting ego networks.

Here's the ego network for "Graph (Discrete Mathematics)". You could do the same thing with this one: extract interesting topics, and then go learn about them. Let's look at another.

I thought this one was interesting as well. There's a lot I've never heard of that make me curious to learn more. Let's look at another.

This (above) is the ego network for "Graph Theory", one of the original searches. There's lots of interesting topics, and even a page relating to Graph Databases.

Here's a cool ego network relating to Artificial Intelligence. I can see cool topics such as Causal AI, Social Intelligence, Philosophy of Artificial Intelligence, Ethics of Artificial Intelligence, and more.

Apparently, one of the picked up Wikipedia pages had to do with fallacies and that ego network is interesting as well. This would be a very interesting rabbit hole to continue down. Perhaps it might be interesting to use "List of fallacies" as a seed search for the edgelist generator and see where it leads us. Maybe I will do that on another day.
What's the Takeaway?
I've long said that the internet is a goldmine for discovery and analysis, if you learn how to use it as such. That is the reason for my obsessions in Natural Language Processing and Network Science. Natural Language Processing gives me answers regarding content and context. Network Science helps me understand relationships and flow.
What I've demonstrated today can be a very useful tool for anyone to use for learning. You don't have to use my seed search terms. You can use your own. You could research any topic at all that interests you. For instance, I will use this to build a network relating to some of my favorite scientists and science fiction authors.
I want to encourage you to JUMP IN and try this stuff out. It feels good to create your own networks and do your own network analysis. You can share edgelists with the community, and you can discover insights that you would likely not discover, otherwise.
And now, we have a tool that we can use to make this #100daysofnetworks adventure a lot more interesting, beyond using stale NetworkX network generators (Les Miserables, etc) or other people's datasets. Research what interests you, and then use that data to build skill. Then the skill sticks, and you learn neat things in the process.
If you would like to learn more about networks and network analysis, please buy a copy of my book!